End-to-End Engineering & Analytics
Creating real-time connections to track stock prices by index & date using cloud computing & solutions
Scroll ↓
Project Overview
Create an EC2 instance to host Kafka server. Use SSH to login to the instance and install Java and Kafka
Start Zookeeper, Kafka-Server, Kafka-Producer, and Kafka-Consumer server on the EC2 instance
Create a S3 bucket for the daily stock price data from the Kafka consumer
Write Python code to create a Kafka Producer and Kafka Consumer to interact with Kafka on our EC2 instance
Simulate our data streaming by sampling data for Kafka Producer & Consumer
Use Crawler to generate a schema for our Glue Table
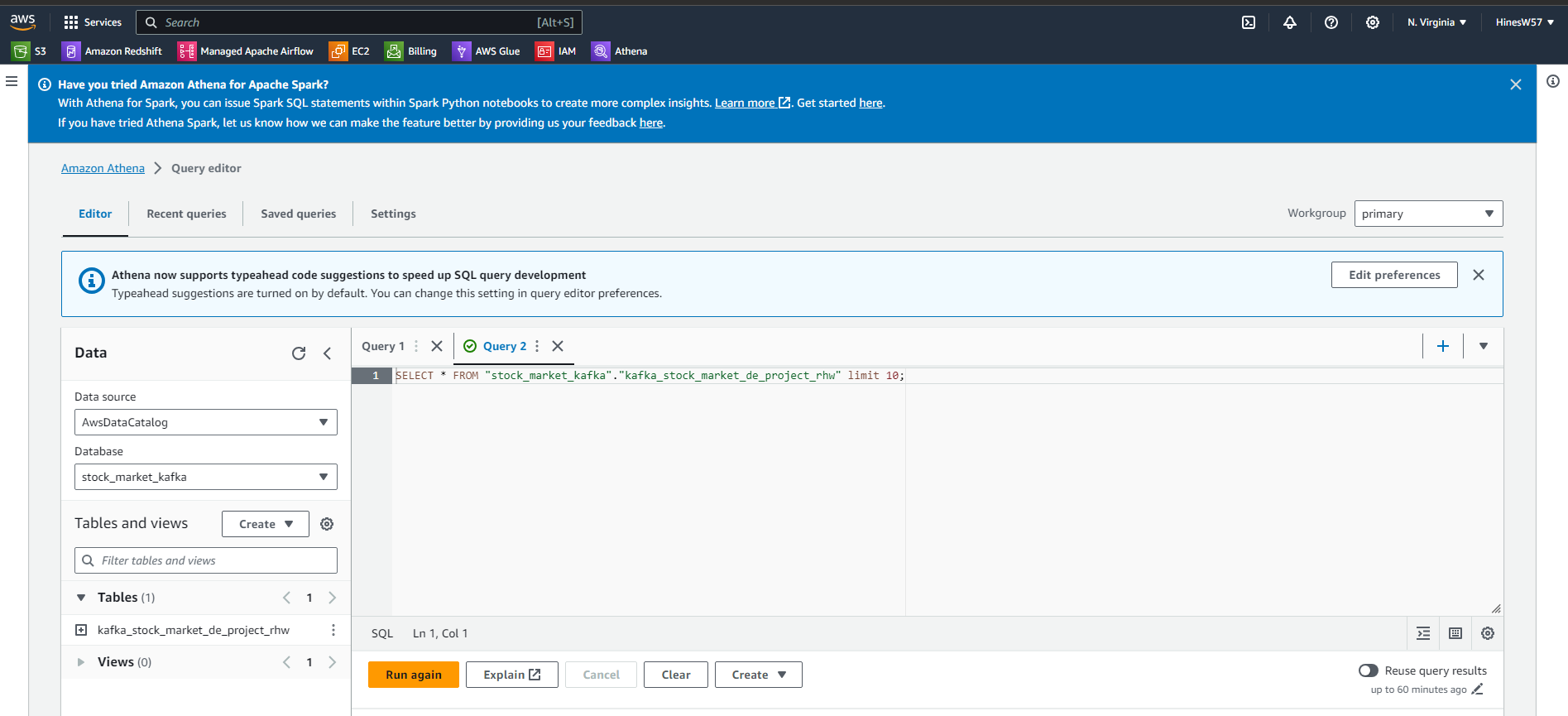
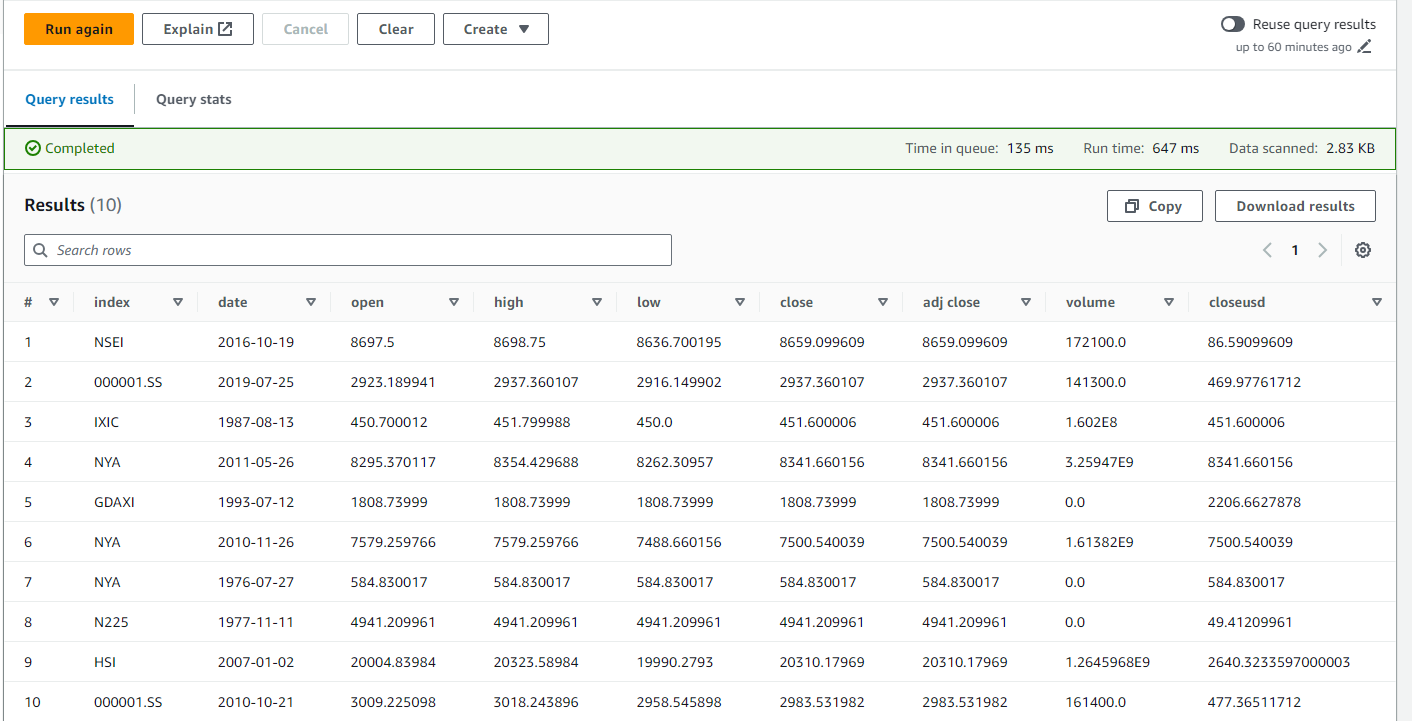
Query live data stream using AWS Athena
Tools Used
Apache Kafka
Amazon EC2
Apache Zookeeper
Amazon S3
Amazon Crawler
AWS Glue Data Catalog
Amazon Athena
Github Link
Want More Details? ↓
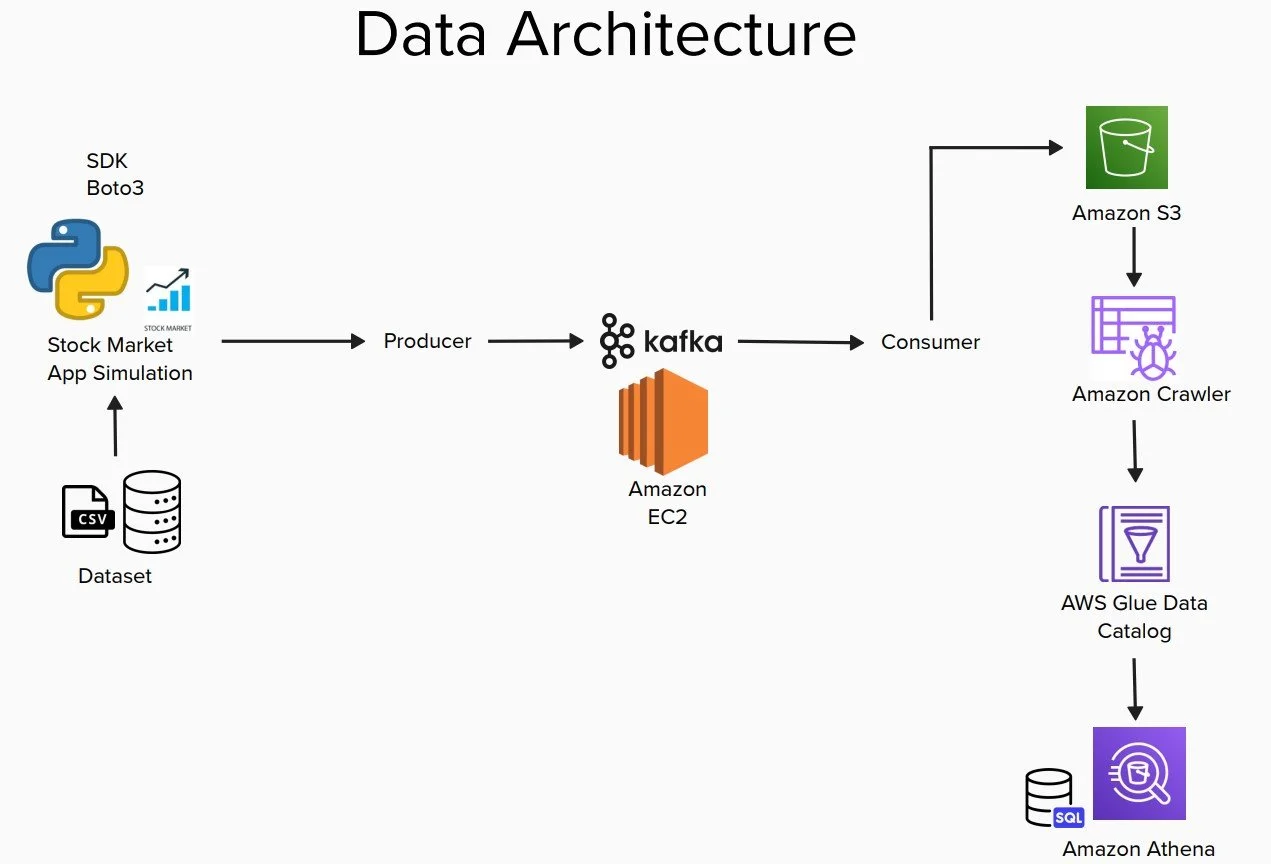
Data Architecture
Step 1
With this project, I wanted to create a real-time connection with stock price data that could be queried for insights. The first step was to create a map of the data architecture. While I just use a CSV for the initial data, this setup would allow me to switch to another data source like an API.
Into the Cloud & Creating VMs
Step 2
After conceptualizing how the tables would work, I created an AWS EC2 instance that would eventually hold our Kafka server.
Hosting Kafka on an AWS EC2 instance offers flexibility, scalability, and integration with AWS services while requiring manual administration and expertise. After spinning up that instance, I used SSH to log in and install Java & Kafka.

Step 3
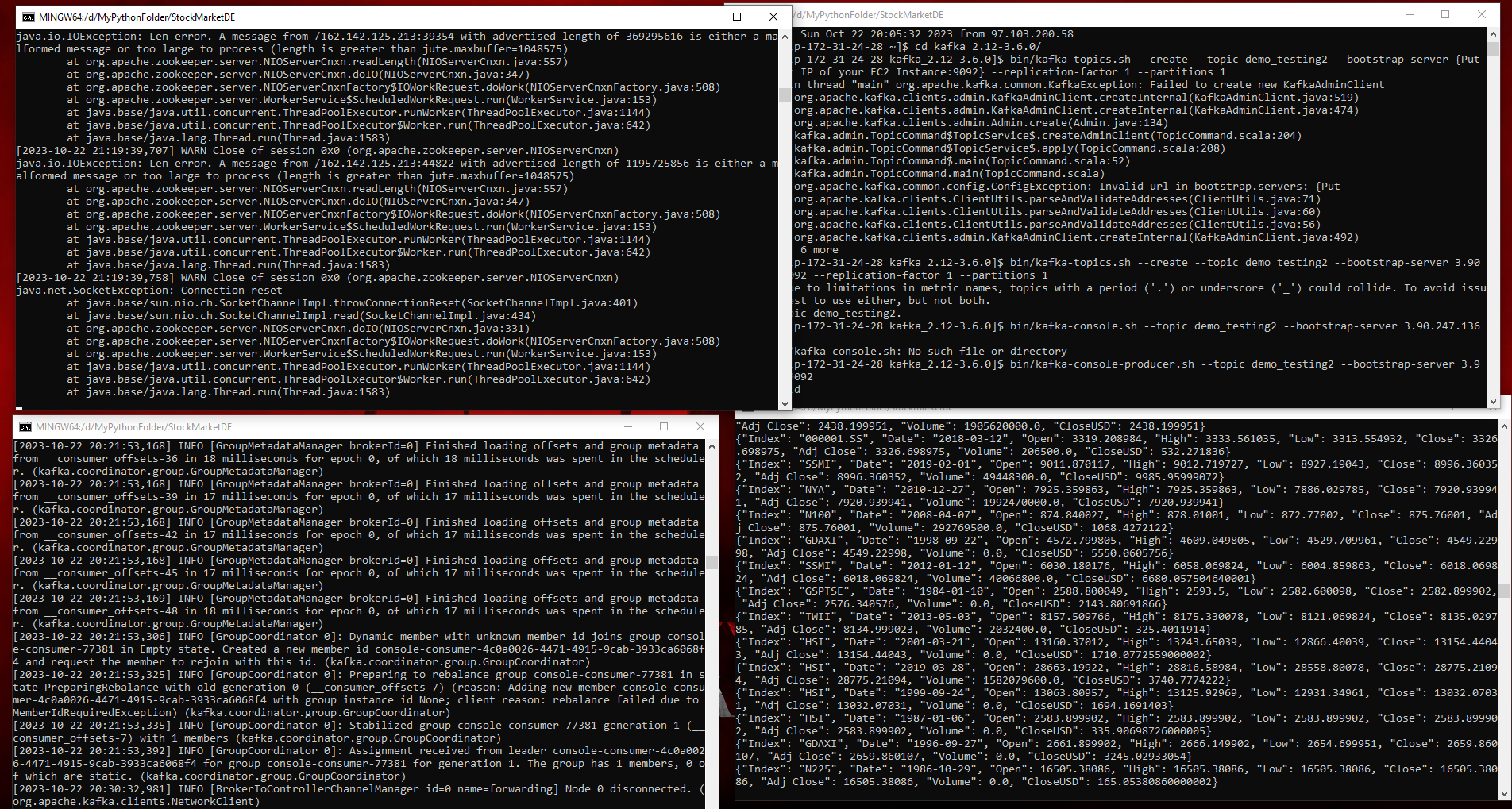
Next, I started Zookeeper, Kafka-Server, Kafka Producer, and Kafka-Consumer on the EC2 instance. I choose ZooKeeper as it acts as a distributed coordination and metadata management that ensures the stability, fault tolerance, and scalability of a Kafka cluster.
I then created an S3 bucket for the data that we will receive from the Kafka consumer.
Creating Code for Producer/Consumer Connections
Step 4
Next, I focused on writing Python code that would help create our next steps. Using Jupyter lab, I created the Kafka Producer and Kafka Consumer code that would then interact with our EC2 instance. The Python code acts as an interface between the Producer and Consumer.

Finalizing & Querying Data Tables
Step 5
To simulate our data streaming, I used a function to sample the datafile every second with the Kafka Producer and send that to our Kafka Consumer. I then used Crawler to generate a schema for our Glue Table on the data in our S3 bucket. Crawler is useful as it streamlines the data management process, enhances data governance, and empowers organizations to leverage their data assets more effectively.


Step 6
From here, I can query our live data stream using AWS Athena to query the S3 buckets directly. I also created a new S3 bucket to store the results of our queries. After all of that hard work, we can now see the real-time daily stock data by index, date, open price, close price, and other variables!